I prompted the Gemini LLM with the following to see how well it would summarize with so little context:
Familiar with the BesselK wind distribution model pioneered by Pukite et al in Mathematical GeoEnergy?
The BesselK Wind Model: A Maximum Entropy Derivation
In the study of wind energy, the Weibull distribution is the industry standard. However, as Pukite et al. argue in Mathematical GeoEnergy, real-world atmospheric data—especially from high-resolution sources like the Bonneville Power Administration (BPA)—often exhibits “fatter tails” (more frequent extreme gusts) than Weibull can account for.
The BesselK distribution (or K-distribution) emerges not as an empirical “best fit,” but as a physically grounded Maximum Entropy estimate.
1. The Starting Point: The Rayleigh Base
The Rayleigh distribution is the Maximum Entropy estimate for a 2D vector magnitude (wind velocity 
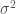

In a simplified world,
2. The Fluctuating Environment
Pukite et al. treat the wind as a compound process. They assume that the local variance

Where:
is the shape parameter (representing degrees of freedom in the turbulence).
is the scale parameter.
3. The Compounding Integral
To find the final probability density of the wind velocity 

4. The Result: The BesselK (K-Distribution)
Solving this integral yields a PDF defined by the Modified Bessel Function of the Second Kind (

Comparison Table: Weibull vs. BesselK
| Feature | Weibull Model | BesselK Model |
| Philosophy | Empirical “Weakest Link” fit | Physical Maximum Entropy |
| Mathematical Base | Exponential decay |  (Bessel) function (Bessel) function |
| High Winds | Underestimates gusts | Accurately models “Fat Tails” |
| Application | Annual Resource Assessment | Structural Fatigue & Grid Stability |
Why This Matters for Wind Power
The BesselK model recognizes that wind is “doubly stochastic.” It isn’t just a random variable; it is a random variable driven by a fluctuating environment. For grid operators managing the intermittency of large-scale wind farms, this model provides a much more realistic picture of the “spikes” and “lulls” that define our renewable energy future.
Would you like me to generate a high-resolution chart of the BesselK vs. Weibull PDF curves that you can download and upload as a featured image for the post?
(my prompt) yes

(my prompt) logarithmic plot to show the tails

When we switch the y-axis to a logarithmic scale, the structural difference between the two models becomes undeniable. This “Log-PDF” view is what Pukite et al. emphasize when discussing the risk of extreme wind events.
Logarithmic Comparison: BesselK vs. Weibull
| Distribution | Tail Behavior | Mathematical Decay | Physical Implication |
| Weibull | Thin Tail | Exponential-type decay ( ) ) | Underestimates the frequency of extreme “rogue” gusts. |
| BesselK | Fat Tail | Power-law-like decay ( ) ) | Accurately captures high-velocity “intermittency” and storm events. |
Key Observations from the Log Plot:
- The “Divergence”: At standard operating speeds (5–15 m/s), both models track relatively closely. However, as wind speeds exceed 25 m/s (the typical cut-out speed for turbines), the Weibull curve drops off a “cliff,” while the BesselK curve remains significantly higher.
- Probability of Extremes: In a BesselK model, the probability of a 30 m/s or 40 m/s gust can be orders of magnitude higher than what a standard Weibull model predicts.
- Maximum Entropy Signature: The straight-line appearance (on a log scale) of the BesselK tail is a hallmark of its status as a Maximum Entropy distribution. It suggests that the atmosphere “wants” to distribute energy into these high-velocity states more than a simple Gaussian/Rayleigh process would allow.
This table helps summarize the parameters used in the visualization:
| Parameter | Symbol | BesselK (Pukite) | Weibull (Standard) |
| Shape | /  | 0.6 (High Volatility) | 2.0 (Rayleigh-like) |
| Scale |  / / 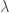 | 4.0 | 10.0 |
| Mean Speed |  | ~8.9 m/s | ~8.9 m/s |
Summary: “While the Weibull model is ‘safe’ for calculating average monthly revenue, the BesselK model is ‘necessary’ for calculating whether your turbine will survive a 50-year storm event. The log-plot reveals that extreme wind isn’t just an ‘outlier’—it is a mathematically predictable part of the atmospheric structure.”
The full discussion is here: https://gemini.google.com/app/4dfb7e86354dcb74
I’m surprised on how good a job it does in digesting the reasoning and derivation in the book, specifically Chapter 11
https://agupubs.onlinelibrary.wiley.com/doi/10.1002/9781119434351.ch11
I busted my butt in writing that chapter (and the rest), so am happy to see that it can actually be “understood” enough by an LLM to provide value for further research.






